高并发系统:数据库优化-读写分离
依据一些云厂商的 Benchmark 的结果,在 4 核 8G 的机器上运行 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS。
大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级。
当单机MySQL达不到高并发读请求时的处理方案:主从读写分离
主从读写的两个技术关键点
一、主从复制
MySQL 的主从复制是依赖于 binlog 的,主从复制就是将 binlog 中的数据从主库传输到从库上。具体过程:
- 从库在连接到主节点时会创建一个 IO 线程,用以请求主库更新的 binlog,并且把接收到的 binlog 信息写入一个叫做 relay log 的日志文件中
- 而主库也会创建一个 log dump 线程来发送 binlog 给从库;
- 从库还会创建一个 SQL 线程读取 relay log 中的内容,并且在从库中做回放,最终实现主从的一致性。
这是一种比较常见的主从复制方式。
主从复制存在的问题
- 数据延时问题
为了不影响主库的性能,主从同步为异步过程。不能保障从库无延时同步。 - 主从的一致性和写入性能的权衡
如果你要保证所有从节点都写入成功,那么写入性能一定会受影响;如果你只写入主节点就返回成功,那么从节点就有可能出现数据同步失败的情况,从而造成主从不一致,而在互联网的项目中,我们一般会优先考虑性能而不是数据的强一致性。 - 不能无限制增加从库数量
增加从库主库会创建log dump线程,消耗主库性能,一般一个主库最多挂 3~5 个从库
主从数据延时解决方案参考
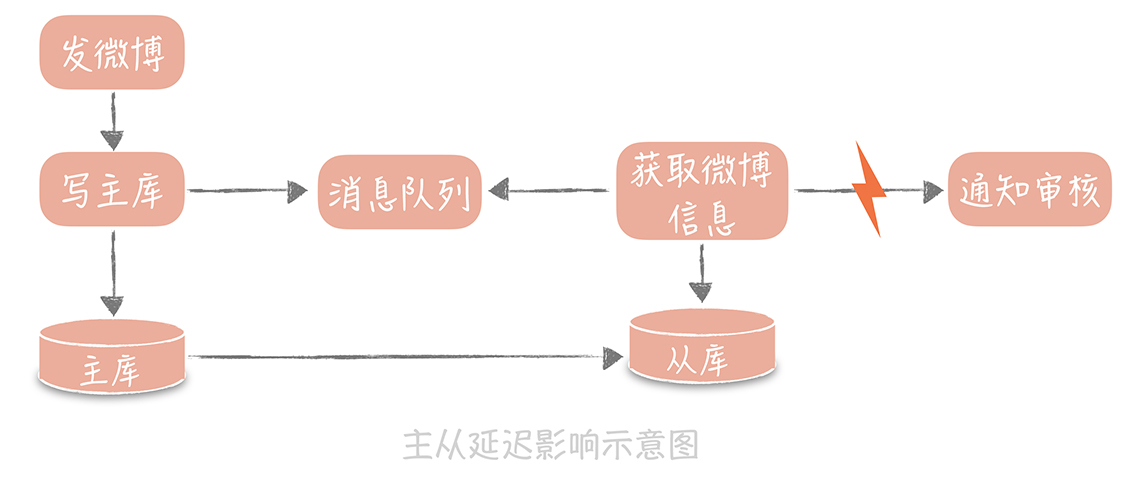
1. 数据冗余
异步消息传输时,不仅仅发送ID,而是发送全量信息,避免从库再次查询.
**缺点:**可能造成单条消息比较大,从而增加了消息发送的带宽和时间。
2. 使用缓存
同步写数据库的同时,将数据写入缓存:如Redis,从Redis中读取。
**缺点:**更适合新增数据,更新数据需要考虑数据不一致问题
注意:需要做好从库延时时间的监控,延时过大需要告警通知。正常的时间是在毫秒级别,一旦落后的时间达到了秒级别就需要告警了。
二、程序访问
一主多从,读写分离,存在多个数据库节点,程序需要选择性的连接,增加了访问的复杂度。
为了降低实现的复杂度,业界涌现了很多数据库中间件来解决数据库的访问问题,这些中间件可以分为两类。
1. 内嵌组件
以淘宝的 TDDL为代表,以代码形式内嵌运行在应用程序内部,你可以把它看成是一种数据源的代理,它的配置管理着多个数据源,每个数据源对应一个数据库,可能是主库,可能是从库。当有一个数据库请求时,中间件将 SQL 语句发给某一个指定的数据源来处理,然后将处理结果返回。
**优点:**简单易用,没有多余的部署成本
**缺点:**缺乏多语言的支持,升级比较困难
2. 增加代理层
单独部署的代理层方案,中间件部署在独立的服务器上,业务代码如同在使用单一数据库一样使用它,实际上它内部管理着很多的数据源,当有数据库请求时,它会对 SQL 语句做必要的改写,然后发往指定的数据源。
市面很多成熟中间件,具体可参考:分布式数据库中间件TDDL、Amoeba、Cobar、MyCAT架构比较
优点:
* 使用标准的 MySQL 通信协议,所以可以很好地支持多语言
* 独立部署,维护升级方便
缺点:
* 增加代理层,SQL多跨一层网络,有性能损耗
* 代理层专人维护成本增加
注意:在使用任何中间件的时候一定要保证对于中间件有足够深入的了解,否则一旦出了问题没法快速地解决就悲剧了。
名词解释
- **QPS:**每秒查询数,是针对读请求的
- **TPS:**每秒执行事务数,倾向于写请求
- **binlog:**记录 MySQL 上的所有变化并以二进制形式保存在磁盘上二进制日志文件