高并发系统:数据库优化-分库分表
在 4 核 8G 的云服务器上对 MySQL 5.7 做 Benchmark,大概可以支撑 500TPS 和 10000QPS,如果出现写并发量大时,该如何解决?出现数据库容量瓶颈时如何解决?单纯从数据库层面考虑一般采用垂直拆分和水平拆分来解决。
数据库分库分表的方式有两种:一种是垂直拆分,另一种是水平拆分。这两种方式,在我看来,掌握拆分方式是关键,理解拆分原理是内核。所以你在学习时,最好可以结合自身业务来思考。
拆分方式
1、垂直拆分
垂直拆分,顾名思义就是对数据库竖着拆分,也就是将数据库的表拆分到多个不同的数据库中。
垂直拆分的原则一般是按照业务类型来拆分,核心思想是专库专用,将业务耦合度比较高的表拆分到单独的库中。举个形象的例子,就是在整理衣服的时候,将羽绒服、毛衣、T 恤分别放在不同的格子里。这样可以解决我在开篇提到的第三个问题:把不同的业务的数据分拆到不同的数据库节点上,这样一旦数据库发生故障时只会影响到某一个模块的功能,不会影响到整体功能,从而实现了数据层面的故障隔离。
现在大多数公司都采用微服务架构,一般方案为按服务拆库,各服务不进行跨库读写数据。
**优点:**各业务库独立,可以按业务重要性来区别对待,优先保障核心业务库。
**缺点:**不能解决某一个业务模块的数据大量膨胀的问题
2、水平拆分
和垂直拆分的关注点不同,垂直拆分的关注点在于业务相关性,而水平拆分指的是将单一数据表按照某一种规则拆分到多个数据库和多个数据表中,关注点在数据的特点。
一般按业务类型分为两种拆分方式:
字段哈希值拆分
这种拆分规则比较适用于实体表,数据相对独立,无明显时间概念等的数据,比如说用户表,可以先对用户 ID 做哈希(哈希的目的是将 ID 尽量打散)比如拆分成16个库,每库64张表。先对库数量16取余,决定划分到哪个库,后对库中表数量64取余,决定在哪张表。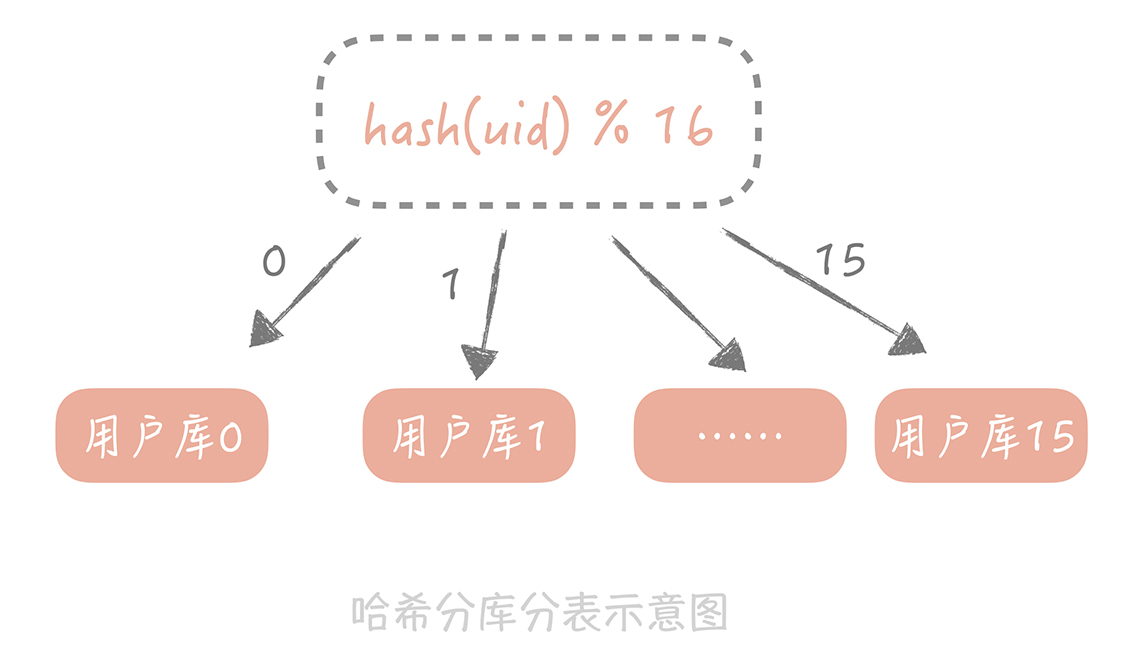
字段区间拆分
比较常用的是时间字段,比如用户订单等按照下单时间来拆分表,用户查询订单时必须指定查询时间段。该例子不一定是最优方案哈,会存在热点问题,比如双十一一天内订单量超大就会存在问题。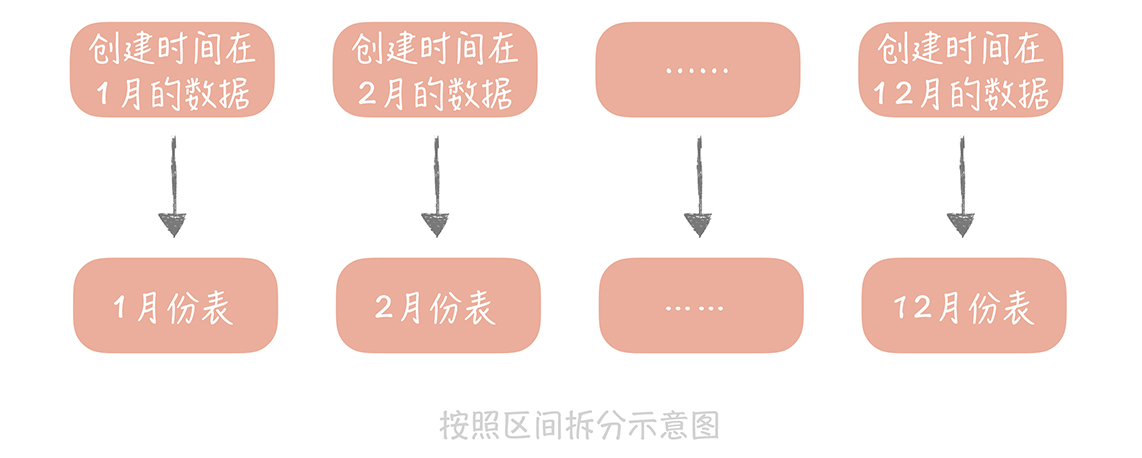
分库分表引入的问题
分库分表引入的一个最大的问题就是引入了分库分表键,也叫做分区键,也就是我们对数据库做分库分表所依据的字段。
一旦分区后,查询条件中必须带有分区键查询,明确要查询的数据在哪个区才有效,否则会带来更严重的性能问题。现阶段如何解决跨区查询问题呢,本人总结方式如下:
1、先查后整合
一般是把两个表的数据取出后在业务代码里面做筛选,复杂是有一些,不过是可以实现的。
2、数据冗余
如用户表按用户ID拆分,但需要按用户昵称查询用户的情况。
可以冗余一份用户昵称与用户ID量字段的表,先从该表中按昵称查询ID,再进行ID精准查询。当然该表也可以进行分区。
3、借助三方中间件
涉及一些复杂的查询搜索功能,可以借助ElasticSearch等中间件,来进行搜索优化。
有很多人并没有真正从根本上搞懂为什么要拆分,拆分后会带来哪些问题,只是一味地学习大厂现有的拆分方法,从而导致问题频出。所以,你在使用一个方案解决一个问题的时候一定要弄清楚原理,搞清楚这个方案会带来什么问题,要如何来解决,要知其然也知其所以然,这样才能在解决问题的同时避免踩坑。